數(shù)字化時(shí)代,企業(yè)對(duì)快速采集日志的需求日益遞增,對(duì)于個(gè)人開(kāi)發(fā)者和企業(yè)來(lái)說(shuō),日志采集也有的截然不同的復(fù)雜度。
“快速”這個(gè)需求的本質(zhì)在于,如何利用比較方便部署且成熟可靠的技術(shù)選型,來(lái)降低搭建一套能滿(mǎn)足業(yè)務(wù)訴求的日志平臺(tái)所需的時(shí)間成本,其中要解決的核心問(wèn)題就是:日志架構(gòu)的復(fù)雜度。在此我們重點(diǎn)聚焦于企業(yè)用戶(hù),深度解析企業(yè)級(jí)的日志平臺(tái)架構(gòu)建設(shè)復(fù)雜度以及建設(shè)思路分享。
01. 企業(yè)級(jí)日志架構(gòu)復(fù)雜度
一套企業(yè)級(jí)的日志平臺(tái)架構(gòu)建設(shè)復(fù)雜度總結(jié)歸納下來(lái),主要體現(xiàn)在三個(gè)方面:
- 采集端部署分散;
- 服務(wù)端部署組件多;
- 日志流對(duì)性能有一定要求。
1)采集端部署分散
比較常用的采集器是開(kāi)源的filebeat,filebeat功能強(qiáng)大,安裝配置也相對(duì)簡(jiǎn)單。但問(wèn)題在于,一旦需要采集的對(duì)象數(shù)量多起來(lái),種類(lèi)多起來(lái),或者這些采集對(duì)象是動(dòng)態(tài)變化的,即使單節(jié)點(diǎn)安裝簡(jiǎn)易的filebeat也會(huì)需要花費(fèi)大量的精力來(lái)安裝和維護(hù)。這也是很多企業(yè)在建設(shè)統(tǒng)一日志平臺(tái)面臨的一個(gè)實(shí)際問(wèn)題。這時(shí),運(yùn)維往往會(huì)寫(xiě)腳本去批量下發(fā),能做到部分解決問(wèn)題,但是后期的配置維護(hù)、版本更新等等,都將帶來(lái)新的問(wèn)題。
那么,有什么方案可以解決呢?有,那就是采取集中管理的思路,由一個(gè)統(tǒng)一的控制中心,通過(guò)在不同節(jié)點(diǎn)上安裝代理來(lái)收集信息+下發(fā)配置。一般一個(gè)中大型企業(yè),基本都會(huì)有一套自己的agent來(lái)控制各方資源,agent往往是在虛擬機(jī)模板或者容器鏡像中就已經(jīng)打入,主要的作用也就是上報(bào)信息以及下發(fā)配置。日志的采集便可以利用好這種集中式的管理工具,基于agent做插件來(lái)充當(dāng)采集端,統(tǒng)一管理采集配置(包括路徑、級(jí)別、過(guò)濾、預(yù)處理等等)。
2)服務(wù)端部署組件多
對(duì)于個(gè)人開(kāi)發(fā)者或小規(guī)模企業(yè)來(lái)說(shuō),部署組件多也許還可以接受。拿開(kāi)源的ELK舉例,日志服務(wù)端部署需要Logstash集群和ES集群,以及一個(gè)Kibana的前端,完整一套集群也許就可以解決相當(dāng)體量的日志集中管理。但對(duì)于一家中大型企業(yè)來(lái)講,體量和業(yè)務(wù)復(fù)雜度上來(lái)之后,情況往往是非常復(fù)雜的。
這時(shí)建設(shè)人員可能會(huì)有一種思路:直接采用多套ELK,也能解決問(wèn)題,部署也就寫(xiě)個(gè)腳本的事情,批量復(fù)制,還可以做“物理隔離”。這樣確實(shí)行之有效,但這種方案會(huì)帶來(lái)另外的問(wèn)題,就是日志無(wú)法進(jìn)一步聚合聚類(lèi),導(dǎo)致各業(yè)務(wù)的日志數(shù)據(jù)成了數(shù)據(jù)孤島,如果組織內(nèi)有那種橫向組織,他們就需要來(lái)回切換集群進(jìn)行諸如日志檢索,日志清洗等操作。
要解決這個(gè)問(wèn)題,其實(shí)只需要再增加一個(gè)服務(wù)端,能夠?qū)⒎植荚诓煌珽LK的日志存儲(chǔ)統(tǒng)一管理起來(lái),讓上述場(chǎng)景統(tǒng)一通過(guò)這個(gè)服務(wù)端提供的接口完成,也就能在使用日志的時(shí)候,不再受到存儲(chǔ)分散的影響。
3)性能要求高
日志數(shù)據(jù)不同于指標(biāo)類(lèi)數(shù)據(jù),日志數(shù)據(jù)無(wú)論是從時(shí)間密度還是從空間密度上來(lái)說(shuō)都要遠(yuǎn)遠(yuǎn)大于其他類(lèi)型的觀測(cè)數(shù)據(jù)。因此,中大型企業(yè)的大型業(yè)務(wù)系統(tǒng)以及龐大的基礎(chǔ)設(shè)施產(chǎn)生的日志量讓企業(yè)開(kāi)發(fā)者不得不思考這其中的性能和成本如何平衡。
總結(jié)三個(gè)關(guān)鍵的性能瓶頸以及對(duì)應(yīng)的解決方案:
① 分散到集中存儲(chǔ)所消耗的帶寬壓力:
- 通過(guò)采集端做預(yù)先過(guò)濾
- 分多條傳輸鏈路
- 做好網(wǎng)絡(luò)鏈路規(guī)劃,盡量避免跨域傳輸
② 清洗和存儲(chǔ)壓力:
- 通過(guò)Kafka等消息隊(duì)列做寫(xiě)入緩沖
- 使用非結(jié)構(gòu)化分片存儲(chǔ)
③ 檢索響應(yīng)速度的壓力:
- 冷熱數(shù)據(jù)分離,減少索引大小
- 完善數(shù)據(jù)預(yù)處理和清洗,索引高效(一定程度依賴(lài)日志輸出規(guī)范化)
02. 整體技術(shù)架構(gòu)
1)整體技術(shù)架構(gòu)介紹
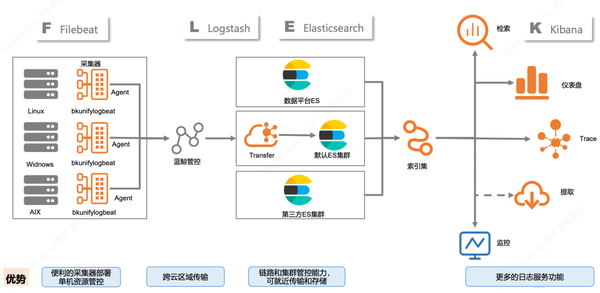
2)藍(lán)鯨平臺(tái)在騰訊內(nèi)部業(yè)務(wù)場(chǎng)景的探索
其實(shí)剛剛展示的這套日志架構(gòu),源自騰訊IEG藍(lán)鯨日志平臺(tái)的數(shù)據(jù)流示意圖。
藍(lán)鯨平臺(tái)在早期就將日志的各類(lèi)應(yīng)用場(chǎng)景作為整個(gè)自動(dòng)化運(yùn)營(yíng)中的關(guān)鍵環(huán)節(jié),并規(guī)劃建造出了一套適合中大型企業(yè)使用的日志平臺(tái)。直至目前,藍(lán)鯨日志平臺(tái)已經(jīng)歷經(jīng)上百次的迭代,在騰訊內(nèi)部積累了大量的實(shí)踐經(jīng)驗(yàn),支持了上千項(xiàng)業(yè)務(wù)的日志需求,總結(jié)出了不少技術(shù)優(yōu)化舉措,在此結(jié)合這個(gè)話題進(jìn)行分享總結(jié)。
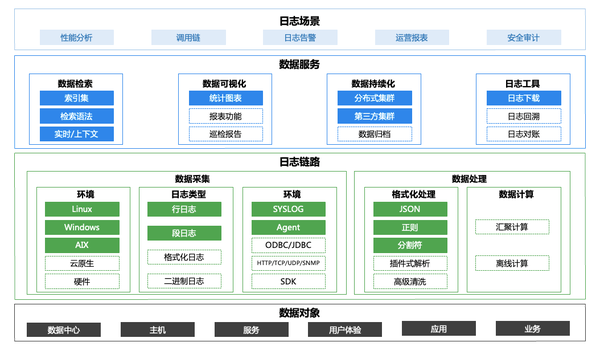
3)關(guān)鍵技術(shù)優(yōu)化舉措&經(jīng)驗(yàn)
- 采集端統(tǒng)一Agent,用Agent裝采集插件的方式來(lái)實(shí)現(xiàn)日志采集,便于安裝管理。
- 對(duì)于難以運(yùn)行Agent的設(shè)備,可以采取用一些節(jié)點(diǎn)主動(dòng)調(diào)用接口獲取syslog的方式,集中存儲(chǔ)再用Agent采集。
- Transfer預(yù)處理和Kafka高吞吐銜接,加強(qiáng)數(shù)據(jù)管道性能。
- 統(tǒng)一存儲(chǔ)端管理,支持第三方ES接入,通過(guò)索引集的設(shè)計(jì)拓展后續(xù)的日志應(yīng)用場(chǎng)景。
- 分析類(lèi)的計(jì)算任務(wù)會(huì)借助已有的成熟的數(shù)據(jù)平臺(tái),而并非在自己內(nèi)部進(jìn)行。
- 數(shù)據(jù)可視化重點(diǎn)關(guān)注指標(biāo)和維度的體系建設(shè),而并非界面的優(yōu)化(grafana可以解決絕大部分可視化需求)。
- 各服務(wù)節(jié)點(diǎn)均可云原生集群化部署。
4)實(shí)踐效果
通過(guò)Agent,支持各類(lèi)日志的采集。
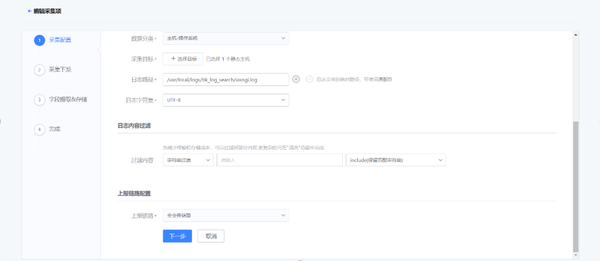
統(tǒng)一服務(wù)端后,使用索引集進(jìn)行跨節(jié)點(diǎn)的日志檢索。
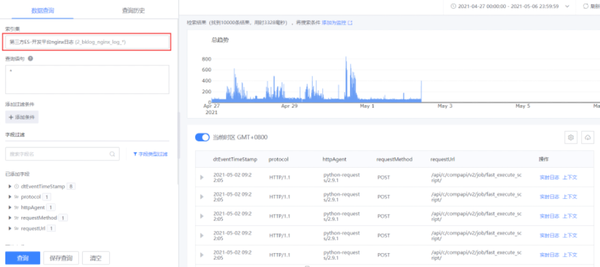
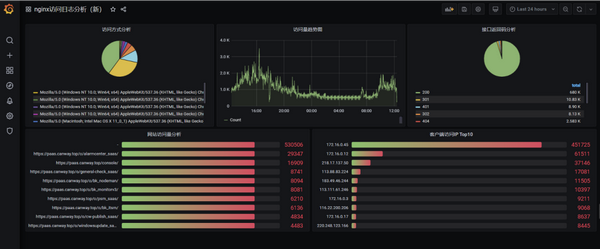
配合grafana分析日志清洗后的指標(biāo)數(shù)據(jù)(以Nginx訪問(wèn)日志為例)。
相關(guān)文章推薦
ITSM運(yùn)營(yíng):服務(wù)請(qǐng)求管理持續(xù)改進(jìn)

 2025-04-11
2025-04-11
查看詳細(xì)


AI驅(qū)動(dòng)IT運(yùn)維轉(zhuǎn)型:從審批流到AI工作流
2025-04-11
查看詳細(xì)
國(guó)產(chǎn)化替代實(shí)踐:嘉為藍(lán)鯨全棧智能觀測(cè)中心對(duì)比IBM Tivoli
2025-04-11
查看詳細(xì)
嘉為藍(lán)鯨平臺(tái):三位一體,打造云原生數(shù)字化基座
2025-04-11
查看詳細(xì)
嘉為藍(lán)鯨DevOps研發(fā)效能管理平臺(tái):AI賦能研運(yùn),效能再進(jìn)化
2025-04-11
查看詳細(xì)
ITSM運(yùn)營(yíng):事件管理持續(xù)改進(jìn)
2025-04-07
查看詳細(xì)







